
What are Durable Functions? A visual JavaScript primer
Lydia Hallie· 9/18/2024 · 10 min read
Modern web applications often require long-running tasks that need to be resilient to external errors and interruptions. If such long-running tasks aren't handled propertly, any error could lead to data inconsistencies, financial losses, poor user experiences, and overall system failures.
These are features like API integrations, AI-powered workflows, data exports, automated billing systems, user onboarding sequences, or even recurring notifications.
Durable Functions offer a simpler, more streamlined solution for managing long-running tasks that need to withstand interruptions and failures. They provide a powerful framework for building resilient, stateful applications, removing the need for manual error and retry management.
In this article, we'll explore what Durable Functions really are, the problems they solve, and how JavaScript developers can get started with Durable Functions through Inngest's Javascript SDK.
Traditional Approach
Imagine we have an e-commerce platform where orders go through several stages: payment processing, inventory checks, shipment scheduling, and notification updates.
Traditionally, we might manage these stages using a mix of background and Cron jobs. Background jobs are tasks that run in the background independently of user interactions, often used for operations like processing payments or updating inventory. Cron jobs are scheduled tasks that run at certain times or intervals, useful for tasks like nightly inventory checks or daily order shipment scheduling.
.png)
While this method works, it's important to handle potential errors properly. In this case, the checkInventory Cron job failed at 9:00, which could lead to outdated stock levels if not handled properly. This, in turn, can cause overselling, missed restocking, and general fulfillment delays.
Additionally, if the server goes down or there's an unexpected delay, our Cron job tasks fail to execute and won't retry automatically. Unless we explicitly give the instructions to retry the failed Cron job, our UI will remain broken until at least 10:00, when the next Cron job is scheduled.
💡 To summarize, our traditional approach had a few downsides:
- Lack of State Management: Background jobs typically don't maintain their state between executions. If a job fails midway, it often needs to start from the beginning, potentially leading to duplicate work or inconsistent results.
- Inefficient Error Handling: While we can implement basic retry mechanisms, it's challenging to manage complex error handling and recovery scenarios.
- Long-Running Processes: Background jobs are usually designed for relatively short-lived tasks. Managing processes that may run for hours or days becomes increasingly complex.
- Scalability Concerns: As the number of background jobs grows, it becomes increasingly challenging to manage their execution, monitor them, and handle errors.
Durable Functions
Now, let's reimagine the same e-commerce platform using Durable Functions. But first, what are Durable Functions?
The term "durable" in Durable Functions refers to the workflow's ability to maintain state and logic through failures, retries, and pauses. A Durable Function guarantees a start-to-finish execution; once it's started, it will eventually complete its execution regardless of any unexpected issues.
.png)
This is what makes Durable Functions special because this wasn't the case with our traditional setup.
In a Durable Function, each task in the order processing workflow is broken down into modular, independent steps. For example, the order processing workflow could include steps for validating payment, checking inventory, scheduling shipment, and updating the customer.
Inngest's SDK allows you to create steps through the step.run function.
const orderProcessingWorkflow = inngest.createFunction({ id: "Order Processing" },{ event: "order.placed" },async ({ step, event }) => {const paymentConfirmation = await step.run("process-payment", () =>processPayment(event.data.orderDetails));const inventoryStatus = await step.run("check-inventory", () =>checkInventory(event.data.orderDetails.items));const shipmentDetails = await step.run("schedule-shipment", () =>scheduleShipment(event.data.orderDetails));await step.run("send-notification", () =>sendNotification(event.data.customerId,"Order Received",shipmentDetails.status));});
Each step is capable of handling failures and can automatically retry based on predefined policies, ensuring that all parts of the order processing sequence are executed correctly.
Durable Functions can also include waits that pause the process for necessary delays (e.g., waiting for a third-party shipment confirmation) without consuming resources. This can be more efficient than traditional CRON jobs, which are less time flexible and can over-consume resources by continuously polling for status updates.
Inngest's SDKS allows you to create waits through several methods, one of which is the step.waitForEvent function.
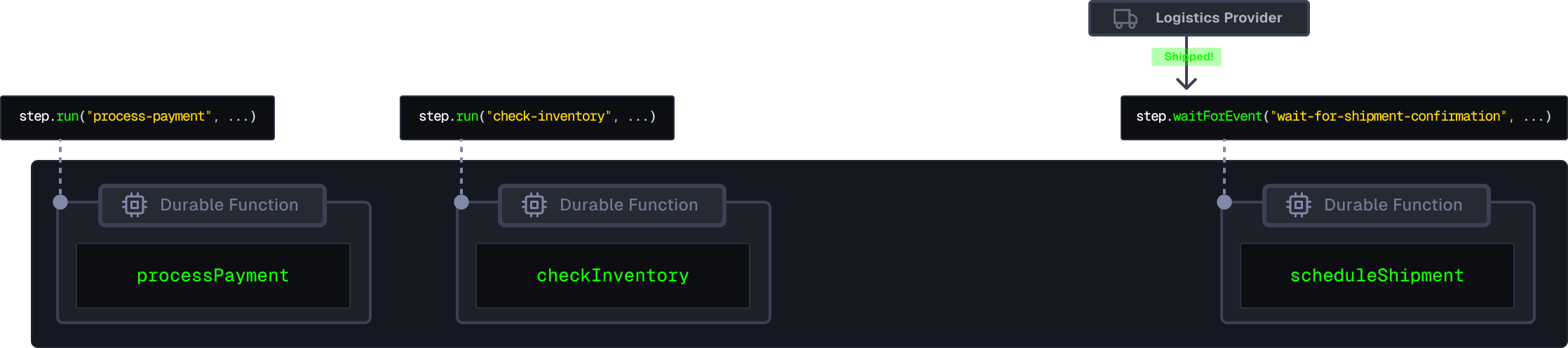
This function is used to pause the execution of a workflow step until a specific event is received, or if a timeout occurs.
const orderProcessingWorkflow = inngest.createFunction({ id: "Order Processing" },{ event: "order.placed" },async ({ step, event }) => {const paymentConfirmation = await step.run("process-payment", () =>processPayment(event.data.orderDetails));const inventoryStatus = await step.run("check-inventory", () =>checkInventory(event.data.orderDetails.items));await step.run("schedule-shipment", () =>scheduleShipment(event.data.orderDetails));await step.run("notify-customer", () =>sendNotification(event.data.customerId, "Order Received"));const shipment = await step.waitForEvent("wait-for-shipment-confirmation", {event: "shipment/create",timeout: "7d",if: "event.data.id == async.data.orderId",});if (shipment) {await step.run("send-notification", () =>sendNotification(event.data.customerId, "Order Shipped"));}});
In this workflow, after scheduling the shipment, the workflow enters a wait state up to 7 days using the step.waitForEvent function. The step.waitForEvent function enables our workflow to wait for a new "shipment.created” matching the same orderId. This wait pauses the workflow until the logistics provider confirms the shipment has been dispatched. Unlike regular background jobs, this wait doesn't use resources while it waits, making it better for handling time-sensitive tasks in web apps.
💡 To summarize, our Durable Function approach enhances the efficiency and reliability of long-running tasks compared to the traditional approach:
- Robust State Management: Each step in a Durable Function is capable of maintaining its state between executions. This prevents the need to restart tasks from the beginning if they fail, minimizing the risk of duplication or inconsistent results.
- Advanced Error Handling: Durable Functions are equipped with built-in mechanisms for error detection and automatic retries, which can be tuned to address specific recovery scenarios. This not only improves the reliability of task execution but also reduces the manual oversight that was required with the traditional approach.
- Efficient Long-Running Process Management: Each task within a Durable Function is treated as a modular step that can independently handle long durations of activity. This modularity allows for more scalable and manageable processes, overcoming the limitations of traditional background jobs that are typically optimized for shorter tasks.
- Enhanced Scalability: As the complexity and number of tasks grow within an application, Durable Functions provide a scalable framework that simplifies monitoring and managing these tasks. The independent steps ensure that the performance and stability of one does not affect others, which is a common challenge with traditional background jobs.
Under the hood
Durable Functions provide these features automatically, but how do they work behind the scenes? Let's explore what happens when we run our e-commerce code snippet step-by-step using Inngest's Durable Execution Engine and SDK.
Before we start, we first need to understand that:
- The Inngest Platform hosts the Durable Execution Engine. The engine is responsible for managing the queue of pending function runs, and maintaining the state of ongoing or pending Function steps.
- The Durable Execution Engine interacts with the Inngest SDK through HTTP requests. Through this communication, the engine provides states and collects updated states from the SDK.
- The functions need to be served through HTTP endpoints. In this step-by-step example, let's assume that we've successfully done this.
⚠️ Note: The illustrations are simplified to improve readability.
Here's a run of our orderProcessingWorkflow():
- An
"order.placed"event is sent to Inngest. In this case, this is done within our application's customapi/orderendpoint, which for example can be triggered when an order is placed. This sends an HTTP request to the Inngest Platform. - Inngest's Platform receives this request, which in turn triggers the engine to identify the matching functions. Within the engine, it creates a new job for the execution of the matching function (
orderProcessingWorkflowin this case), and queues this job.
- The engine picks up this job when it's first in the queue, and sends a request to your app's
/api/inngestendpoint. This request includes all the information that the SDK needs to runorderProcessingWorkflowand the state indicating that step #1 hasn't run yet. - The SDK receives this request. It executes
orderProcessingWorkflow, and runs step #1.
- After running step #1, the SDK sends a request to the engine with the data from step #1, and a request to run step #2.
- The Engine receives the response with the incremental state update, stores it, and picks up the run again.
- The Engine sends a request to the SDK which indicates that step #2 should be run next.
- The SDK receives this request. It re-runs the entire workflow, but skips step #1 since this has already been memoized. It then discovers step #2, and executes this.
- The SDK returns a response with step #2's state and return value, and information that lets the SDK know run step #3 next.
This process continues, with the Engine and SDK communicating back and forth, executing steps, and managing state until the entire workflow is completed. When the workflow has been completed, the SDK responds with a 200 OK response, and the job is removed from the jobs queue.
Throughout the workflow, any step that encounters an issue executes predefined error-handling routines. Let's see what happens behind the scenes if "check-inventory" were to throw an error:
- The SDK tries to execute
check-inventory, but an exception is thrown (in real life, this could be caused by e.g. a server timeout). The SDK catches this, returns anerrorobject in the response, and includes a default retry configuration if none is provided. - The Engine receives the error response, stores the run state including error details, and schedules a retry based on the retry configuration (default is 4 retries).
- After the first delay of 15 seconds, the Engine initiates the first retry by resending another request. The SDK skips
process-paymentas this is already memoized, and attempts to runcheck-inventoryagain. In this case, the second attempt succeeds.
If it were to fail again, the process repeats from step 3. This retry cycle continues until either the step succeeds or the maximum retries (4 by default) are exhausted. If all retries are exhausted, the Engine marks the step and workflow as failed, and stores the final error state for debugging and potential manual intervention.
This durable retry mechanism automatically handles transient errors, giving each step multiple chances to succeed without manual intervention. By preserving the workflow state, it can seamlessly continue once the error is resolved.
Conclusion
Durable Functions make it easy to manage complex, long-running processes in modern applications. With their built-in state management, error handling, and resumability, they let developers focus on the app's main functions instead of infrastructure.
While this article focuses on JavaScript and Inngest's SDK, Durable Functions can be used in many programming languages and platforms. For JavaScript developers, especially with frameworks like Next.js, Durable Functions provide a great method to enhance your app's capabilities as they integrate seamlessly with external services, AI workflows, and other advanced features that demand resilience and long-term execution.
As systems get more complex, using Durable Functions will make your apps more reliable, scalable, and easier to maintain, leading to better software solutions.
Help shape the future of Inngest
Ask questions, give feedback, and share feature requests
Join our Discord!